Aidan Gomez
The Neural Turing Machine
This article serves to briefly outline the design of the Neural Turing Machine (NTM), a backpropogatable architecture that can (among many possibilities) learn to dynamically execute programs.
I’ve added some specifications about the NTM’s architecture that the paper excludes for the sake of generality. These will be discussed upon presentation.
The Neural Turing Machine was proposed by Graves et al. as a Turing-Complete network capable of learning (rather complex) programs. Inspired by the sequential nature of the brain, and the large, addressable memory of the computer.
The NTM is composed of five modules:
- The controller
- The addressing module
- The read module
- The write module
- The memory
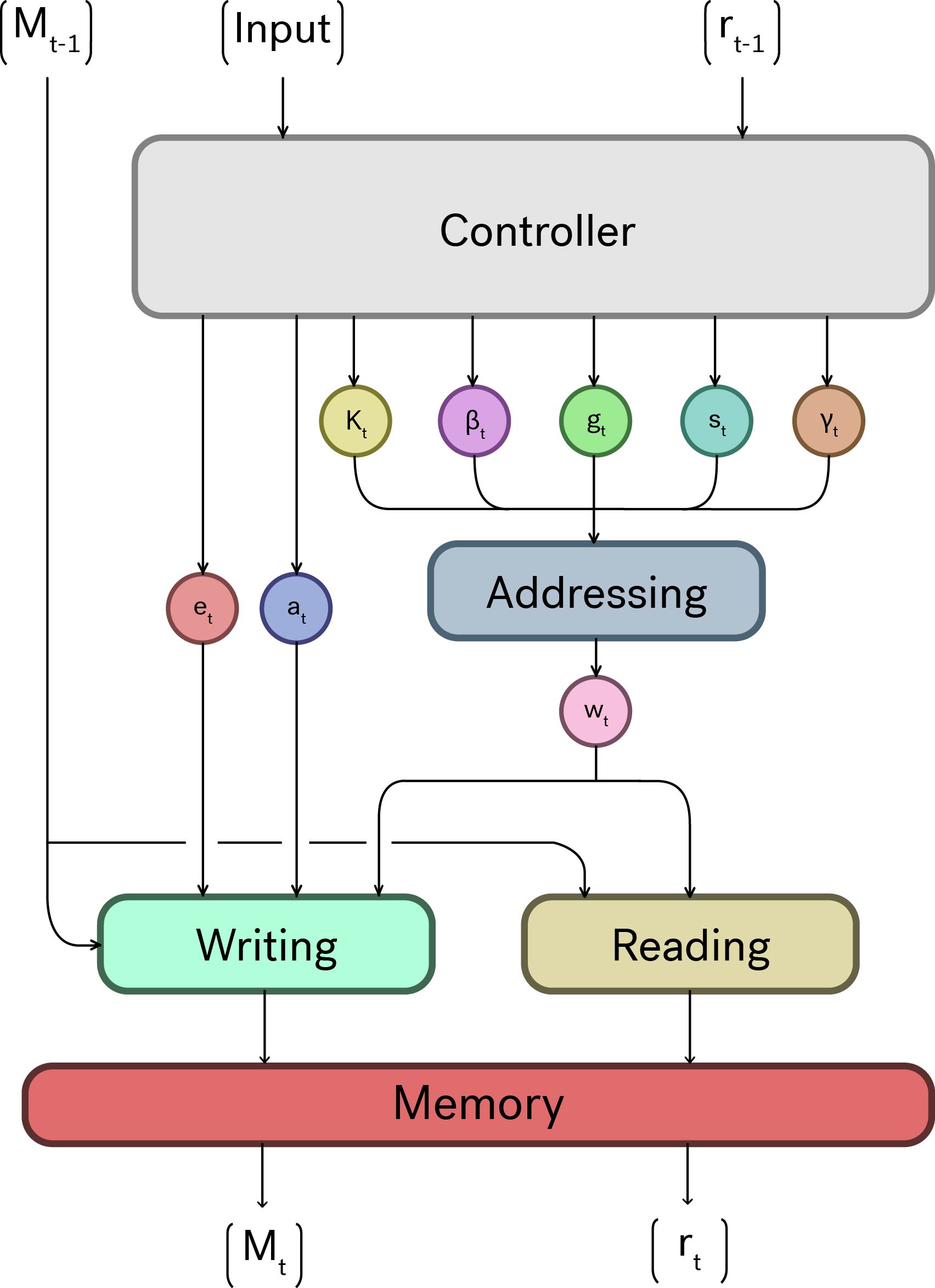
The Controller
The controller acts as the interface between input data and memory. It learns to manage its own memory through addressing.
The paper maintains that the controller can be of any format, it simply needs to read in data and produce the outputs required by the sub-modules. They choose an LSTM for their implementation.
The parameters depended upon by the sub-modules are:
- the key vector; Compared against the memory when addressing by content similarity.
- the key strength; A weighting effecting the precision of the content addressing.
- the blending factor; A weight to blend between content addressing and previous time-step addressing.
- the shift weighting; A normal distribution across the allowed shift amounts.
- the sharpening exponent; Serves to sharpen the final address
- erase vector; Similar to an LSTM, decides what memory from the previous time-step to erase.
- add vector; The data to be added to memory.
The Addressing Module
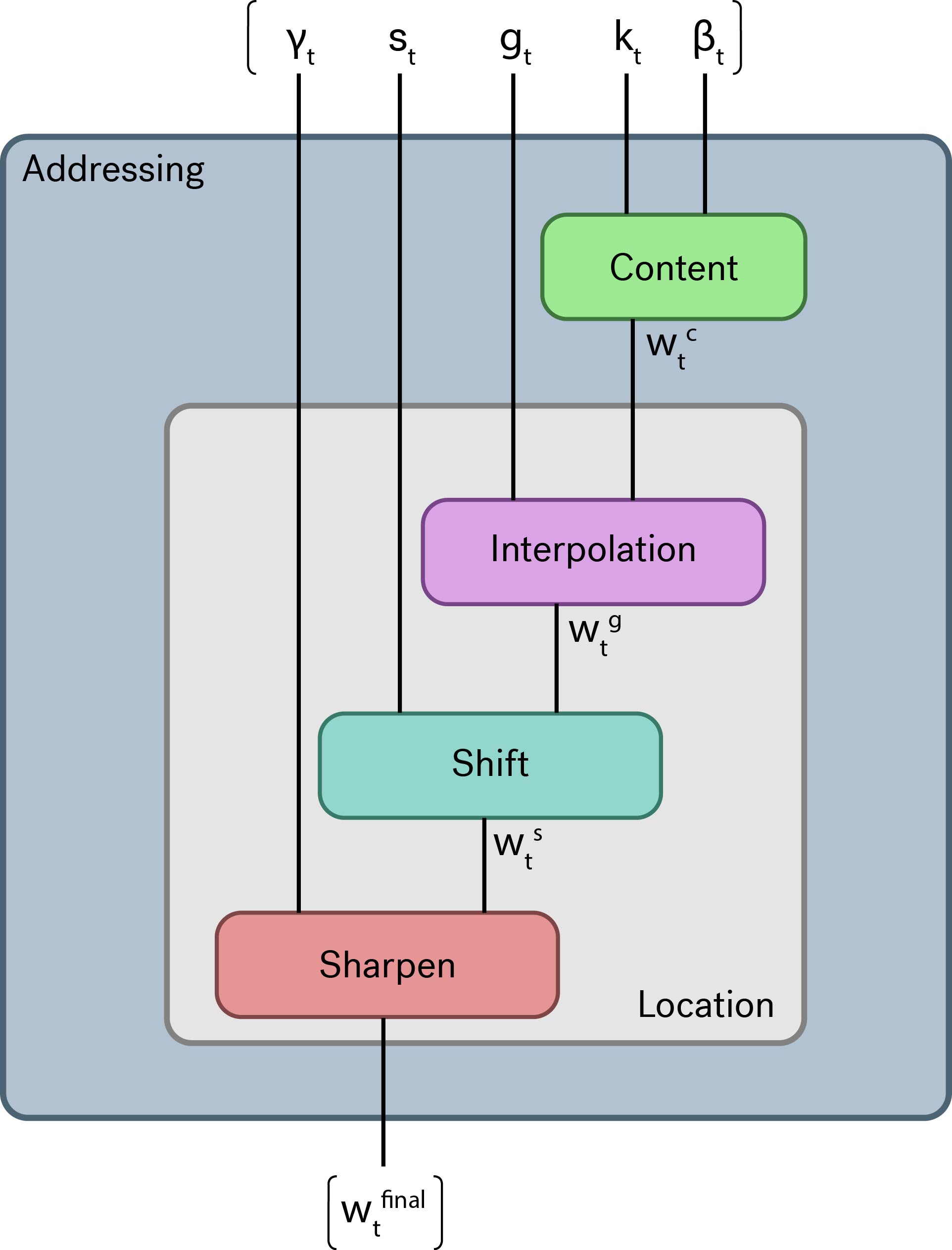 This module generates a window over the memory for the read and write heads.
This module generates a window over the memory for the read and write heads.
Accessing by content similarity
This module effectively laps over the memory comparing each block to the key vector and creates a normally distributed weighting over the memory based of the similarity.
where is an example difference function.
Accessing by location
This module has 3 steps:
- The controller decides how much of the previous time-step’s weighting should be preserved (using ).
- It then performs a shift of the weighting (using ).
- Finally it sharpens (using ) and normalizes the weighting.
Read & Write
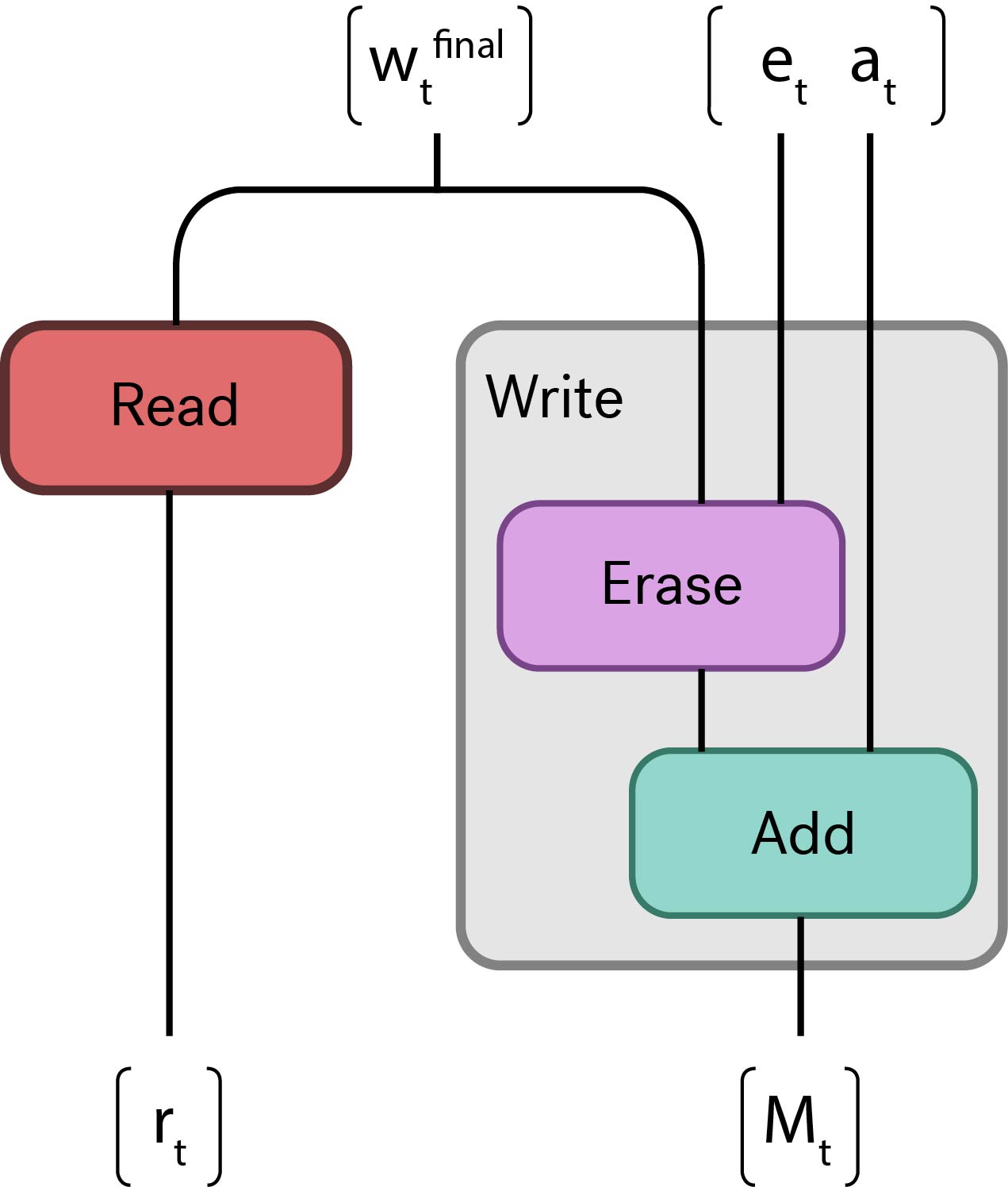
Reading
Pretty straight-forward.
Writing
Writing is performed in two steps, similar to how an LSTM updates its state.
- The erase vector removes memory that is no longer relevant.
- The new data is placed in memory (using ).
Significance
This architecture has already had an impact on a multitude of research projects (notably, the Neural GPU) and I have great faith it will continue to do so. There’s been much discussion over the past couple of years about computers programming themselves, and I believe this has been the greatest stride towards that end-goal.
The Neural Turing Machine is a reactionary computer, changing behaviour based on its “environment”. It certainly will play a major role in setting precedence for the way neural networks will be applied for the purpose of AI.
I look forward to reading more of the work done by the Google DeepMind and OpenAI teams.
If there are any errors in my description please do not hesistate to reach out to me at hello@aidangomez.ca.