Aidan Gomez
Backpropogating an LSTM: A Numerical Example
Let’s do this…
We all know LSTM’s are super powerful; So, we should know how they work and how to use them.
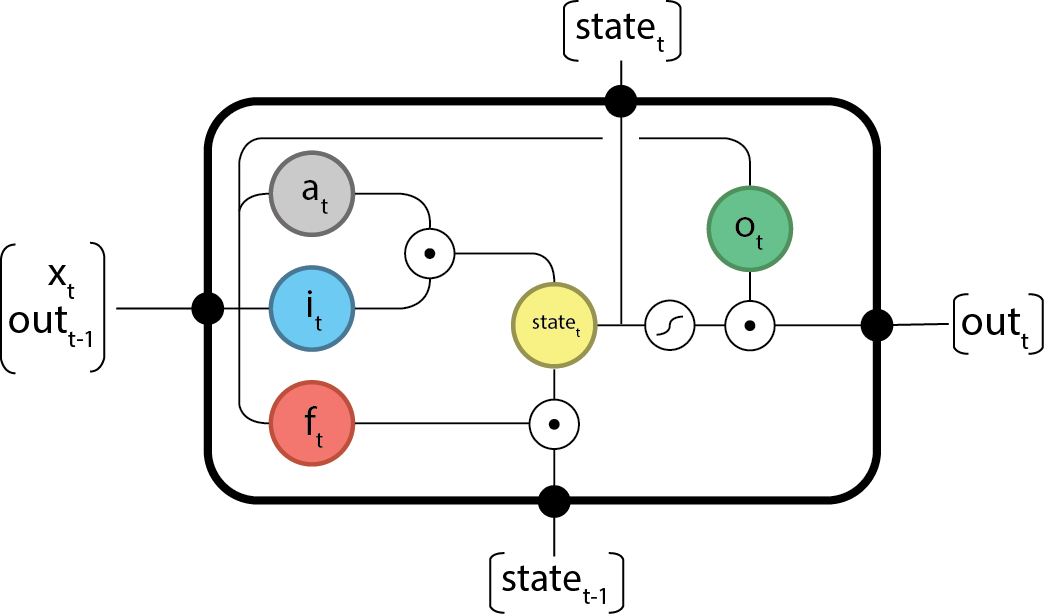
Syntactic notes
- Above is the element-wise product or Hadamard product.
- Inner products will be represented as
- Outer products will be respresented as
- represents the sigmoid function:
The forward components
The gates are defined as:
- Input activation:
- Input gate:
- Forget gate:
- Output gate:
Note for simplicity we define:
Which leads to:
- Internal state:
- Output:
The backward components
Given:
- the output difference as computed by any subsequent layers (i.e. the rest of your network), and;
- the output difference as computed by the next time-step LSTM (the equation for t-1 is below).
Find:
The final updates to the internal parameters is computed as:
Putting this all together we can begin…
The Example
Let us begin by defining out internal weights:
And now input data:
I’m using a sequence length of two here to demonstrate the unrolling over time of RNNs
Forward @
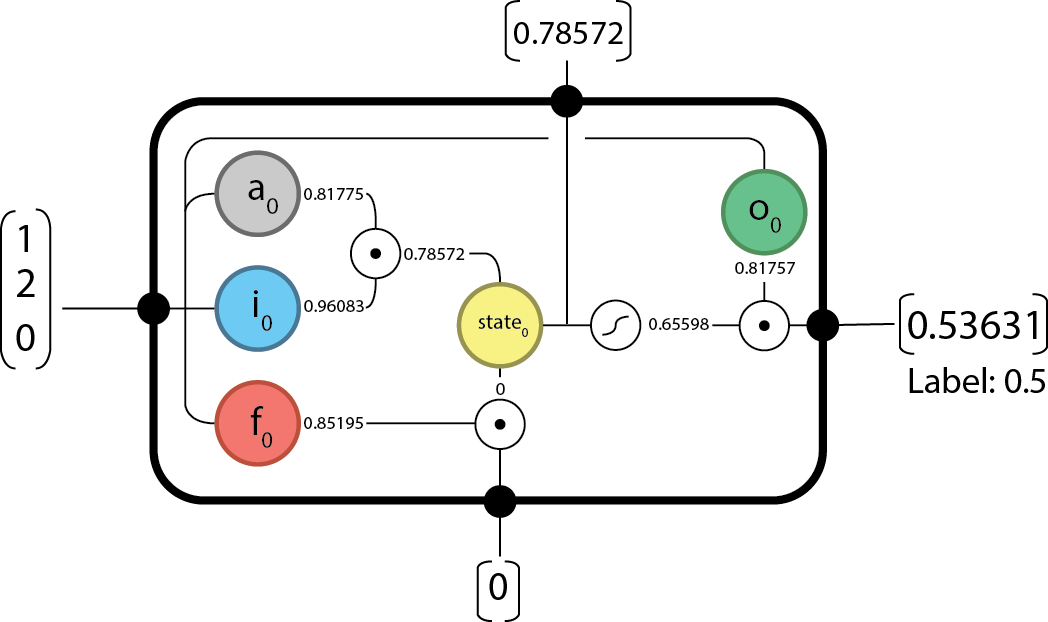
From here, we can pass forward our state and output and begin the next time-step.
Forward @
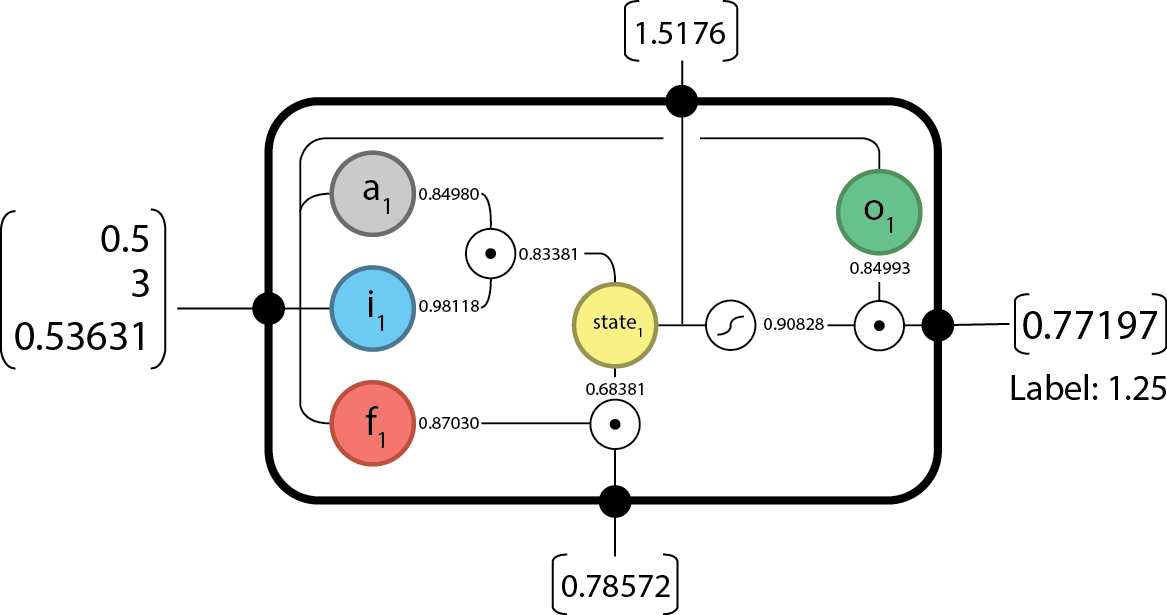
And since we’re done our sequence we have everything we need to begin backpropogating.
Backward @
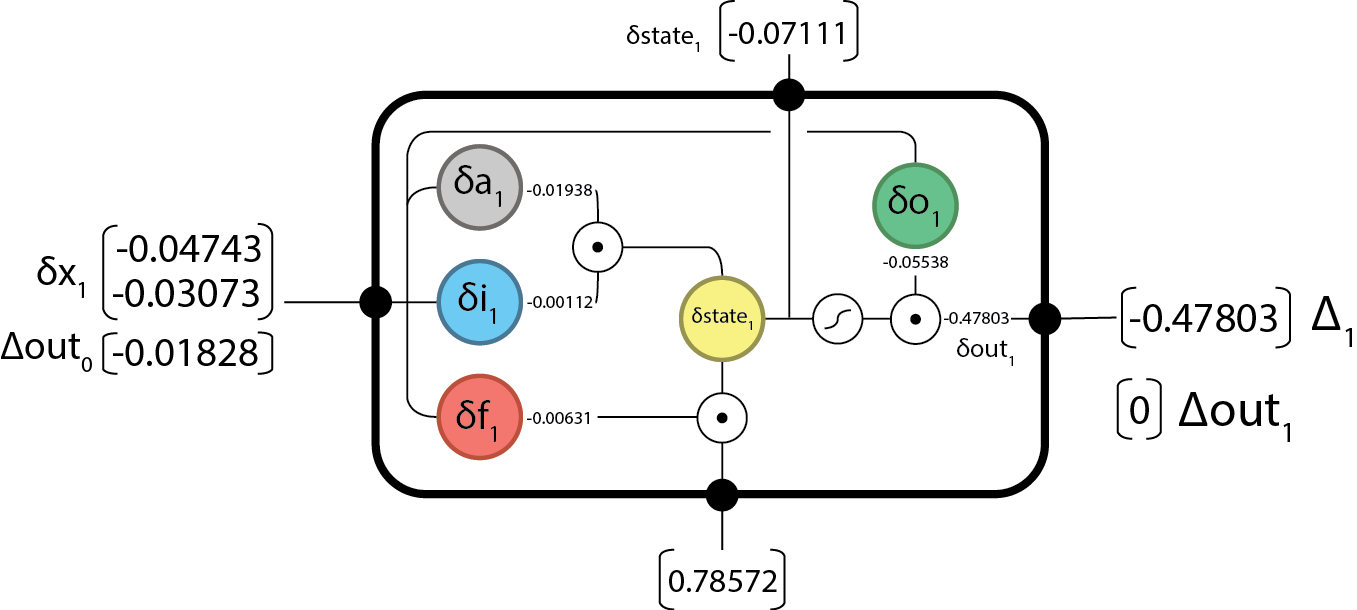
First we’ll need to compute the difference in output from the expected (label).
Note for this we’ll be using L2 Loss: . The derivate w.r.t. is .
because there are no future time-steps.
Now we can pass back our and continue on computing…
Backward @
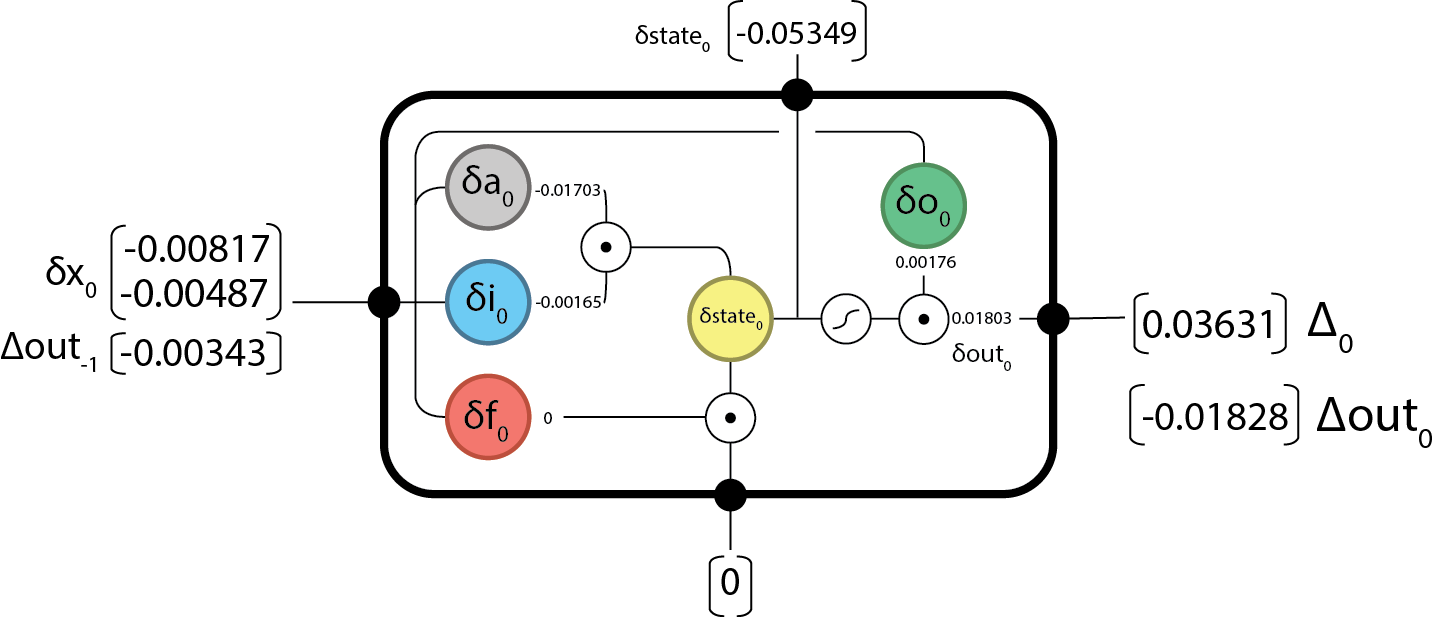
And we’re done the backward step!
Now we’ll need to update our internal parameters according to whatever solving algorithm you’ve chosen. I’m going to use a simple Stochastic Gradient Descent (SGD) update with learning rate: .
We’ll need to compute how much our weights are going to change by:
And updating out parameters based on the SGD update function: we get our new weight set:
And that completes one iteration of solving an LSTM cell!
Of course, this whole process is sequential in nature and a small error will render all subsequent calculations useless, so if you catch ANYTHING email me at hello@aidangomez.ca